Redactionele opmerking: Dit bericht werd oorspronkelijk gepubliceerd op 12 juni 2025.
Wat is milieudetectie?
Zie het als een tijdmachine voor planeet Aarde. Geen flux capacitor, geen DeLorean en geen Marty McFly nodig!😉 Gewoon wat coole technologie waarmee we kunnen zien hoe onze wereld in de loop van de tijd verandert.
Het detecteren en begrijpen van milieuveranderingen is essentieel voor weloverwogen besluitvorming, duurzame ontwikkeling en effectieve risicovermindering bij rampen. Door systematisch trends zoals ontbossing, verstedelijking en kusterosie in een vroeg stadium te identificeren en te monitoren, kunnen beleidsmakers, stedenbouwkundigen, milieuagentschappen en andere relevante belanghebbenden tijdig en proactieve maatregelen implementeren om nadelige gevolgen voor ecosystemen, biodiversiteit en kwetsbare menselijke bevolkingen te beperken.
Veranderingsdetectie levert een essentiële bewijsbasis voor het beoordelen van de effectiviteit van bestaand milieubeleid en natuurbehoudstrategieën. Het speelt ook een sleutelrol bij het informeren van de planning en ontwikkeling van veerkrachtige infrastructuur die toekomstige milieustressoren kan weerstaan. Bovendien, door nauwkeurige en up-to-date informatie te bieden, ondersteunt het een efficiëntere toewijzing van middelen en helpt het bij het prioriteren van gebieden die de grootste risico's lopen.
Bovenal vergroot het vermogen om veranderingen in het milieu te detecteren en te interpreteren het vermogen van de samenleving om te reageren op klimaatgerelateerde uitdagingen zoals zeespiegelstijging, extreme weersomstandigheden en aantasting van habitats. In deze context dient de detectie van veranderingen als een cruciaal hulpmiddel voor het bevorderen van een verantwoordelijker en adaptiever beheer van de planeet in een tijdperk gekenmerkt door snelle en vaak onvoorspelbare transformaties. Hoewel deze “tijdmachine” de geschiedenis niet kan herschrijven, stelt ze ons in staat om van het verleden te leren en een koers uit te zetten naar een duurzamere toekomst.
Voor het avontuur van vandaag gebruik ik Databricks en Apache Sedona, dit zijn in feite de krachtige gereedschappen voor het werken met georuimtelijke gegevens zonder dat je computer smelt. En waar gaan we naartoe? San Francisco,specifiek de SoMa (South of Market) gebied! We gaan kijken hoe het er in augustus 2022 uitzag versus februari 2025. Geloof me, zelfs in slechts een paar jaar tijd kun je verbaasd zijn hoeveel een buurt kan veranderen. Het is als het bekijken van je stad in versnelde weergave.
Implementatie
De volgende implementatie is onderdeel van de training die we aanbieden bij RevoData, specifiek gericht op het benutten van de geospatiale mogelijkheden van Databricks.
Remote sensing en fotogrammetrie omvatten een breed scala aan onderwerpen. Je hebt actieve en passieve sensoren, verschillende soorten resolutie (ruimtelijk, spectraal, temporeel, radiometrisch), georeferencing, orthofoto generatie en analyse van het elektromagnetisch spectrum. In plaats van te verzanden in alle technische details, ga ik me richten op waarom ik bepaalde methoden heb gekozen en welke andere opties potentieel overwogen zouden kunnen worden. Laten we beginnen.
Datasets
Allereerst hebben we data nodig, maar wat voor data? Voor verandringsdetectie in een stedelijke omgeving maken we doorgaans gebruik van satelliet- of luchtbeelden die in ten minste vier spectrale banden zijn vastgelegd: Rood, Groen, Blauw, en Nabij-infrarood. Waarom NIR? Wel, het komt neer op fysica. Verschillende sensoren detecteren verschillende ‘smaken’ van energie, van zichtbaar licht dat onze ogen zien tot onzichtbare infrarood- of microgolven. Elk sensortype onthult unieke informatie over het aardoppervlak op basis van de specifieke energiegolven die het kan meten. Wat de sensor ‘ziet’, hangt af van hoe objecten omgaan met deze golven:
- Absorptie: Het oppervlak neemt de energie op (zoals donker asfalt dat opwarmt in zonlicht)
- Reflectie: de energie kaatst terug (zoals licht dat spiegelt op een meer)
- Transmissie: De energie gaat erdoorheen (zoals zonlicht door helder water)
Verschillende materialen, zoals water, aarde, beton, vegetatie, hebben elk unieke ‘vingerafdrukken’ in hoe ze met deze golven omgaan. Zo kunnen we kenmerken identificeren en monitoren vanaf satellieten of vliegtuigen!
Deze interacties stellen ons in staat om indices zoals de te berekenen Genormaliseerde Verschil Vegetatie Index (NDVI) en de Genormaliseerde Verschil Waterindex (NDWI). Dit zijn eenvoudig en nuttig voor het classificeren van elke beeldpixel als vegetatie, water of onbegroeide grond. U kunt ook een stap verder gaan en algoritmen voor machine learning of patroonherkenning toepassen, zoals de maximum-likelihood-classificator, om verschillende verschijnselen in het landschap te identificeren.
Het goede nieuws? Dit soort beelden is gratis beschikbaar. U kunt de gegevens eenvoudig benaderen in GeoTiff-formaat via de NOAA Gegevens Toegangsviewer en begin je eigen reis door ruimte en tijd.
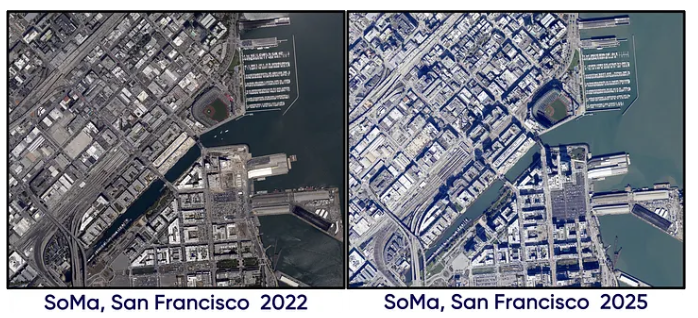
Data-inname
Opnieuw maakt Apache Sedona het binnenhalen van geospatiale data opmerkelijk eenvoudig.
from pyspark.sql.functions import expr, explode, col
from sedona.spark import *
from pyspark.sql.window import Window
from pyspark.sql import functions as F
from pyspark.sql import SparkSession
config = SedonaContext.builder() .\
config('spark.jars.packages',
'org.apache.sedona:sedona-spark-shaded-3.3_2.12:1.7.1,'
'org.datasyslab:geotools-wrapper:1.7.1-28.5'). \
getOrCreate()
sedona = SedonaContext.create(config)
file_urls = {"2022": f"s3://{dataset_bucket_name}/geospatial-dataset/raster/orthophoto/soma/2022/2022_4BandImagery_SanFranciscoCA_J1191044.tif",
"2025": f"s3://{dataset_bucket_name}/geospatial-dataset/raster/orthophoto/soma/2025/2025_4BandImagery_SanFranciscoCA_J1191043.tif"}
df_image_2025 = sedona.read.format("binaryFile").load(file_urls["2025"])
df_image_2025 = df_image_2025.withColumn("raster", expr("RS_FromGeoTiff(content)"))
df_image_2022 = sedona.read.format("binaryFile").load(file_urls["2022"])
df_image_2022 = df_image_2022.withColumn("raster", expr("RS_FromGeoTiff(content)"))
De gegevens verkennen
We kunnen metadata uit de afbeelding van 2025 ophalen door de volgende query uit te voeren:
df_image_2025.createOrReplaceTempView("image_new_vw")
display(spark.sql("""SELECT RS_MetaData(raster) AS metadata,
RS_NumBands(raster) AS num_bands,
RS_SummaryStatsAll(raster) AS summary_stat,
RS_BandPixelType(raster) AS band_pixel_type,
RS_Count(raster) AS count
FROM image_new_vw"""))
Tegels voor schaalbare beeldanalyse
Om de schaalbaarheid te verbeteren en de prestaties in de aankomende analyse te verhogen, verdelen we eerst de afbeelding in kleinere segmenten:
tile_w = 195
tile_h = 191
tiled_df_2025 = df_image_2025.selectExpr(
f"RS_TileExplode(raster, {tile_w}, {tile_h})"
).withColumnRenamed("x", "tile_x").withColumnRenamed("y", "tile_y").withColumn("width", expr("RS_Width(tile)")).withColumn("height", expr("RS_height(tile)"))
window_spec = Window.orderBy("tile_x", "tile_y")
tiled_df_2025 = tiled_df_2025.withColumn("rn", F.row_number().over(window_spec)).withColumn("year", lit(2025))
tiled_df_2022 = df_image_2022.selectExpr(
f"RS_TileExplode(raster, {tile_w}, {tile_h})"
).withColumnRenamed("x", "tile_x").withColumnRenamed("y", "tile_y").withColumn("width", expr("RS_Width(tile)")).withColumn("height", expr("RS_height(tile)"))
window_spec = Window.orderBy("tile_x", "tile_y")
tiled_df_2022 = tiled_df_2022.withColumn("rn", F.row_number().over(window_spec)).withColumn("year", lit(2022))
union_raster = tiled_df_2022.unionByName(tiled_df_2025, allowMissingColumns=False)
window_spec = Window.partitionBy("rn").orderBy(F.desc("year"))
union_raster = union_raster.withColumn("index", F.row_number().over(window_spec))
Beeldclassificatie
We voeren pixel-voor-pixel classificatie uit door de NDVI- en NDWI-indices te berekenen en een eenvoudige beslissingsboom toe te passen. De classificatiecriteria worden niet alleen bepaald door de definities van NDVI en NDWI, maar ook door temporele verschillen tussen de twee beelden, die op verschillende tijdstippen van het jaar en de dag zijn opgenomen. Deze verschillen zijn bijvoorbeeld waarneembaar in de variërende schaduwen die door gebouwen worden geworpen. Zoals bij elke classificatiemethode wordt een zekere mate van verkeerde classificatie verwacht. Vervolgens worden de resultaten naar een Delta-tabel geschreven.
# NDVI berekenen met behulp van de rode en NIR-banden volgens de formule NDVI = (NIR - Rood) / (NIR + Rood)
union_raster = union_raster.withColumn(
"ndvi",
expr(
"RS_Divide("
" RS_Subtract(RS_BandAsArray(tile, 1), RS_BandAsArray(tile, 4)), "
" RS_Add(RS_BandAsArray(tile, 1), RS_BandAsArray(tile, 4))"
")"
)
)
# NDWI berekenen met behulp van de groene en NIR-banden als NDWI = (groen - NIR) / (groen + NIR)
union_raster = union_raster.withColumn(
"ndwi",
expr(
"RS_Divide("
" RS_Subtract(RS_BandAsArray(tile, 4), RS_BandAsArray(tile, 2)), "
" RS_Add(RS_BandAsArray(tile, 4), RS_BandAsArray(tile, 2))"
")"
)
)
# Rode en groene banden als arrays in nieuwe kolommen
union_raster = union_raster.withColumn(
"red",
expr(
"RS_BandAsArray(tile, 1)"
)
).withColumn(
"green",
expr(
"RS_BandAsArray(tile, 2)"
)
)
# Classificatieboom op basis van rode en groene banden en NDVI, NDWI
union_raster = union_raster.withColumn(
"classification",
F.expr("""
transform(
arrays_zip(ndvi, ndwi, red, green),
x ->
CASE
WHEN year = 2022 THEN
CASE
WHEN x.red < 15 AND x.green < 15 THEN 4
WHEN x.ndvi > 0.35 AND x.ndwi < -0.35 THEN 2
WHEN (x.ndvi < -0.2 AND x.ndwi > 0.35) OR (x.red < 15 AND x.ndwi > 0.35) OR (x.ndwi > 0.45) THEN 3
WANNEER x.ndvi >= -0,3 EN x.ndvi <= 0,3 EN x.ndwi >= -0,3 EN x.ndwi <= 0,3 DAN 1
ANDERS 999
EINDE
WANNEER jaar = 2025 DAN
GEVAL
WANNEER x.red < 15 EN x.green < 15 DAN 4
WANNEER x.ndvi > 0,3 EN x.ndwi < -0,15 DAN 2
WANNEER x.ndvi < -0,35 EN x.ndwi > 0,55 DAN 3
WANNEER (x.ndvi >= -0,5 EN x.ndvi <= 0,5 EN x.ndwi >= -0,5 EN x.ndwi <= 0,5) OF (x.ndvi > 0,8 EN x.ndwi > 0,3) DAN 1
ANDERS 999
EINDE
ANDERS 999
EINDE
)
""")
)
# Classificatie-array als nieuwe band in het raster en het definiëren van de waarde 'geen gegevens' als 999
classification_df = (
union_raster
.select("tile_x", "tile_y", "rn", "year", "index", expr("RS_MakeRaster(tile, 'I', classification) AS tile").alias("tile"))
.select("tile_x", "tile_y", "rn", "year", "index", expr("RS_SetBandNoDataValue(tile,1, 999, false)").alias("tile"))
.select("tile_x", "tile_y", "rn", "year", "index", expr("RS_SetBandNoDataValue(tile,1, 999, true)").alias("tile"))
)
classification_df = classification_df.withColumn("maxValue", expr("""RS_SummaryStats(tile, "max", 1, false)"""))
classification_df.withColumn("raster_binary", expr("RS_AsGeoTiff(tile)")).select("tile_x", "tile_y","rn", "year", "index", "raster_binary").write.mode("overwrite").saveAsTable("geospatial.soma.classification")
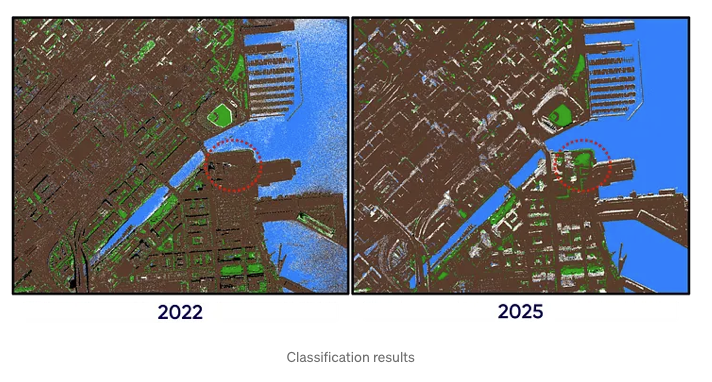
Invullen van ontbrekende gegevens via interpolatie
In de bovenstaande afbeeldingen kunnen we witte gebieden waarnemen, oftewel pixels die niet konden worden geclassificeerd en als no-data waarden zijn achtergelaten. Om dit aan te pakken, kunnen we interpolatie toepassen met behulp van de Inverse Distance Weighting (IDW) methode. Apache Sedona vereenvoudigt dit proces: we filteren de tiles met no-data waarden uit en voeren de interpolatie uit. Daarna slaan we de geïnterpoleerde resultaten op in een Delta-tabel.
# Separating the dataframe into two dataframes based on the
no_interpolation_df = classification_df.filter(classification_df["maxValue"] != 999).select("tile_x", "tile_y","rn", "year", "index", "raster_binary")
interpolated_df = classification_df.filter(classification_df["maxValue"] == 999).select("tile_x", "tile_y","rn", "year", "index", expr("RS_Interpolate(tile, 2.0, 'variable', 48.0, 6.0)").alias("tile")).withColumn("raster_binary", expr("RS_AsGeoTiff(tile)")).select("tile_x", "tile_y","rn", "year", "index", "raster_binary")
union_df = interpolated_df.unionByName(no_interpolation_df, allowMissingColumns=False)
union_df.write.mode("overwrite").saveAsTable("geospatial.soma.interpolation")
union_df = spark.table("geospatial.soma.interpolation").withColumn("tile", expr("RS_FromGeoTiff(raster_binary)"))

Classificatieveranderingen tussen de twee beelden evalueren
Het zou nuttig zijn om een band te creëren die de verschillen tussen de classificaties van 2022 en 2025 benadrukt en deze als derde band in de afbeelding toe te voegen.
union_df.createOrReplaceTempView("union_df_vw")
merged_raster = sedona.sql("""
SELECT rn, RS_Union_Aggr(tile, index) AS raster
FROM union_df_vw
GROUP BY rn
""")
merged_raster.createOrReplaceTempView("merged_raster_vw")
diff_raster = merged_raster.withColumn("diff_band", expr(
"RS_LogicalDifference("
"RS_BandAsArray(raster, 1), RS_BandAsArray(raster, 2)"
")"))
result_df = diff_raster.select("rn", expr("RS_AddBandFromArray(raster, diff_band) AS raster").alias("raster")).withColumn("raster_binary", expr("RS_AsGeoTiff(raster)"))
result_df.select("rn", "raster_binary").write.mode("overwrite").saveAsTable("geospatial.soma.change_detection")
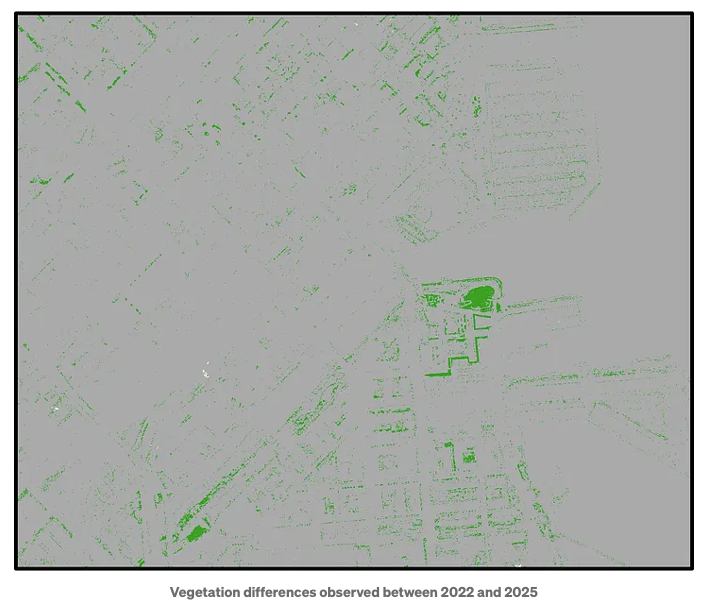
Tenslotte kunnen we veranderingen, zoals die in vegetatie, detecteren en visualiseren, met de onderstaande afbeelding als voorbeeld:
Wat is hierna?
In onze live training “Databricks Geospatial in een dag” bij RevoData Kantoor, zullen we dieper ingaan op de logica achter deze code en dit voorbeeld gebruiken om te demonstreren hoe u:
- GeoTIFF-bestanden visualiseren
- Genereer optimaal gedimensioneerde tegels uit grote rasterdatasets
- Configureer clusters geoptimaliseerd voor rekenintensieve workloads, zoals ruimtelijke interpolatie
- Partitioneer Spark DataFrames op de rasterkolom om de verwerking te versnellen
- Gebruik complementaire tools om tegels naadloos samen te voegen tot een grote GeoTIFF.
Pak hier je plek voor de training via onderstaande link, ik kijk ernaar uit je daar te zien!
https://revodata.nl/databricks-geospatial-in-a-day/

Melika Sajadian
Senior Geospatial Consultant bij RevoData, die haar kennis over Databricks Geospatial met u deelt