Redactionele opmerking: Dit bericht is oorspronkelijk gepubliceerd op 20 juni 2025.
Wat is de Sky View Factor en waarom is het belangrijk in onze steden?
Ik ben terug met een nieuw zonnig, op de zomer geïnspireerd, geospatiaal avontuur!
Heb je je ooit afgevraagd hoeveel lucht je eigenlijk kunt zien als je op een drukke stadsstraat of onder een groep stadse bomen staat? Die zichtbare strook lucht heet de Sky View Factor (SVF) heeft een verrassend grote invloed op hoe steden opwarmen, afkoelen en zelfs hoe comfortabel we ons buiten voelen. Hoe minder lucht je ziet, hoe meer warmte er tussen gebouwen en bomen blijft hangen, waardoor die stedelijke hitte-eilanden, waar stadstemperaturen hoger oplopen dan in omliggende gebieden. Deze hitte-eilanden maken zomerdagen niet alleen ondraaglijk, maar kunnen ook de luchtvervuiling verergeren, de energievraag voor koeling verhogen, de volksgezondheid onder druk zetten door hittegerelateerde ziekten te versterken, en zelfs de slijtage van stedelijke infrastructuur versnellen.
Het meten van de SVF vergt meer dan alleen een weer-app of een snelle satellietopname; je hebt een gedetailleerd, 3D, straatniveau beeld van de stad nodig. Daar waar LiDAR puntwolkgegevens schijnt, waarbij miljarden laser-gescande punten van elk dak, elke boomtop, elke straat en elk trottoir worden vastgelegd. Deze schat aan 3D-gegevens stelt ons in staat om het te modelleren stedelijk bladerdak, het ingewikkelde samenspel van gebouwen en groen dat de doorstroming van zonlicht en lucht door het stadsbeeld regelt. Vanuit dit kunnen we de SVF berekenen en koele fisheye plots dat precies laat zien hoeveel lucht je zou zien als je ergens op de grond lag.

Tijdens mijn masteropleiding hebben mijn medestudenten en ik een app gebouwd voor de gemeente Den Haag. Gebruikers konden op een kaart klikken of een lijst met punten uploaden om SVF-waarden en de mate van bezonning door gebouwen en bomen te verkrijgen. Je kunt ons volledige rapport met de front-end en back-end code bekijken. hier. Destijds voerden we de berekeningen uit met NumPy-arrays en tal van goede, ouderwetse for-lussen. Ik werk het project nu opnieuw met PySpark, met de focus op schaalbare datawarehousing voor big data-analyse in plaats van real-time, on-the-fly-verwerking, zonder diep in te gaan op de onderliggende wiskundige berekeningen. Daar blinkt Databricks in uit: het cloud-native platform verwerkt moeiteloos enorme LiDAR-datasets, waardoor bergen 3D-punten worden omgezet in snelle, bruikbare inzichten. Of je nu een stedenbouwkundige bent die stadsstraten wil afkoelen of simpelweg een nieuwsgierige stedelijke data-ontdekkingsreiziger, het is nog nooit zo makkelijk of leuk geweest om omhoog te kijken en te vragen: hoeveel lucht zien we echt?
Implementatie:
De volgende implementatie is onderdeel van de training die we aanbieden bij RevoData, specifiek gericht op het benutten van de geospatiale mogelijkheden van Databricks.
In deze implementatie wil ik me richten op refactoring van code en de beschikbare opties verkennen om te beginnen met de "laaghangende vruchten", waarbij wordt benadrukt welke delen van de code met minimale wijzigingen kunnen worden aangepast voor gedistribueerde verwerking.
Laten we beginnen!
Datasets
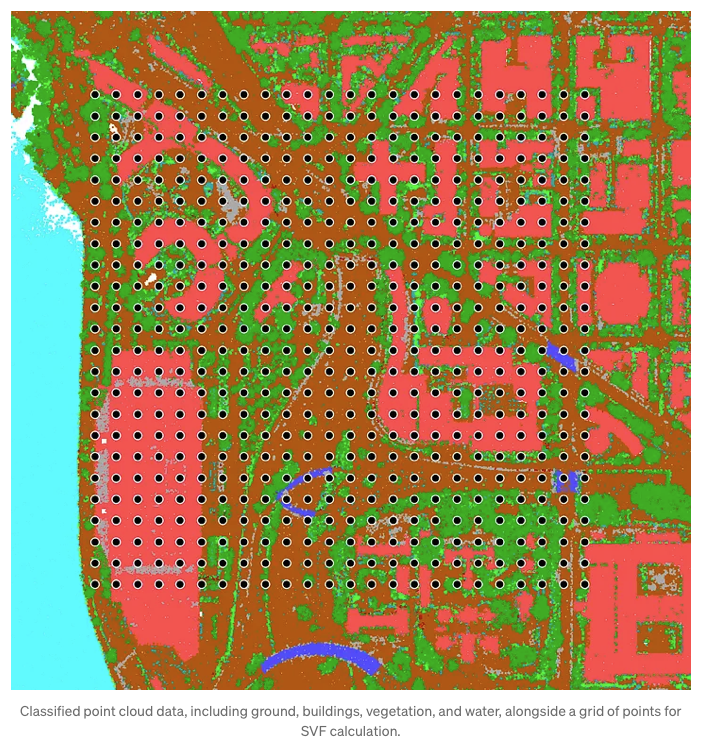
Zoals ik eerder al aangaf, hebben we voor dit project oorspronkelijk gebruik gemaakt van point cloud data van de Gemeente Den Haag. Maar vandaag neem ik je mee naar Washington, deels om voor mezelf wat afwisseling in de omgeving te brengen, en deels zodat je de data makkelijker kunt downloaden vanaf een Engelstalige website. De data is volledig beschikbaar. hier. Ik heb ook een raster van 576 punten over het gebied gegenereerd, dat we zullen gebruiken om de Sky View Factor (SVF) te berekenen.
Importeer bibliotheken
In deze implementatie hebben we een paar bibliotheken nodig die ik in één keer importeer:
import math
import numpy as np
import boto3
import os
import matplotlib.pyplot as plt
import pdal
import json
import io
import pyarrow as pa
from pyspark.sql.functions import col, sqrt, pow, lit, when, atan2, degrees, floor
from pyspark.sql.types import StructType, StructField, DoubleType, FloatType, IntegerType, ShortType, LongType, ByteType, BooleanType, MapType, StringType, ArrayType
import pandas als pd
van sedona.spark import *
van pyspark.sql import functions als F
van pyspark.sql.window import Window
import base64
van PIL import Image
Data-inname
Apache Sedona maakt het invoegen van geospatiale gegevens opmerkelijk eenvoudig voor de gegenereerde grid-punten.
config = SedonaContext.builder() .\
config('spark.jars.packages',
'org.apache.sedona:sedona-spark-shaded-3.3_2.12:1.7.1,'
'org.datasyslab:geotools-wrapper:1.7.1-28.5'). \
getOrCreate()
sedona = SedonaContext.create(config)
# Het pad naar het grid-geopackage en het las-bestand van de puntenwolk
dataset_bucket_name = "revodata-databricks-geospatial"
dataset_input_dir="geospatial-dataset/point-cloud/washington"
gpkg_file = "grid/pc_grid.gpkg"
pointcloud_file = "las-laz/1816.las"
input_path = f"s3://{dataset_bucket_name}/{dataset_input_dir}/{pointcloud_file}"
# Lees de rastergegevens
df_grid = sedona.read.format("geopackage").option("tableName", "grid").load(f"s3://{dataset_bucket_name}/{dataset_input_dir}/{gpkg_file}").withColumnRenamed("geom", "geometry").withColumn("x1", F.expr("ST_X(geometry)")).withColumn("y1", F.expr("ST_Y(geometry)")).select("fid", "x1", "y1", "geometry")
num_partitions = math.ceil(df_grid.count()/2)
Om puntwolkgegevens te verwerken, kunnen we bibliotheken zoals gebruiken laspy of PDAL. In dit geval heb ik PDAL, met een paar optimalisaties voor leestijd om de uitvoerarray efficiënt om te zetten naar een PySpark DataFrame:
def _create_arrow_schema_from_pdal(pdal_array):
"""Maak een Arrow-schema aan op basis van een PDAL-array."""
fields = []
# Wijs PDAL-typen toe aan Arrow-typen
type_mapping = {
'float32': pa.float32(),
'float64': pa.float64(),
'int32': pa.int32(),
'int16': pa.int16(),
'uint8': pa.uint8(),
'uint16': pa.uint16(),
'uint32': pa.uint32()
}
for field_name in pdal_array.dtype.names:
field_type = pdal_array[field_name].dtype
arrow_type = type_mapping.get(str(field_type), pa.float32()) # standaard float32
fields.append((field_name, arrow_type))
return pa.schema(fields)
def _create_spark_schema(arrow_schema):
"""Converteer PyArrow-schema naar Spark DataFrame-schema."""
spark_fields = []
type_mapping = {
pa.float32(): FloatType(),
pa.float64(): DoubleType(),
pa.int32(): IntegerType(),
pa.int16(): ShortType(),
pa.int8(): ByteType(),
pa.uint8(): ByteType(),
pa.uint16(): IntegerType(), # Spark heeft geen types zonder teken
pa.uint32(): LongType(), # Spark heeft geen types zonder teken
pa.string(): StringType(),
# Voeg indien nodig andere typetoewijzingen toe
}
for field in arrow_schema:
arrow_type = field.type
spark_type = type_mapping.get(arrow_type, StringType()) # standaard StringType
spark_fields.append(
StructField(field.name, spark_type, nullable=True)
)
return StructType(spark_fields)
def pdal_to_spark_dataframe_large(pipeline_config, spark, chunk_size=1000000):
"""Streamingversie voor zeer grote bestanden."""
pipeline = pdal.Pipeline(json.dumps(pipeline_config))
pipeline.execute()
# Haal schema op uit eerste array
first_array = pipeline.arrays[0]
schema = _create_arrow_schema_from_pdal(first_array)
# Maak lege RDD
rdd = spark.sparkContext.emptyRDD()
# Verwerk arrays in chunks
for array in pipeline.arrays:
for i in range(0, len(array), chunk_size):
chunk = array[i:i+chunk_size]
data_dict = {name: chunk[name] for name in chunk.dtype.names}
arrow_table = pa.Table.from_pydict(data_dict, schema=schema)
pdf = arrow_table.to_pandas()
chunk_rdd = spark.sparkContext.parallelize(pdf.to_dict('records'))
rdd = rdd.union(chunk_rdd)
# Converteren naar DataFrame
return spark.createDataFrame(rdd, schema=_create_spark_schema(schema))
pipeline_config = {
"pipeline": [
{
"type": "readers.las",
"filename": input_path,
}
]
}
# Zet de puntenwolk-array om naar een Spark DataFrame
df_pc = pdal_to_spark_dataframe_large(pipeline_config, spark)
df_pc = df_pc.withColumn("geometry", F.expr("ST_Point(X, Y)"))
df_pc.write.mode("overwrite").saveAsTable(f"geospatial.pointcloud.wasahington_pc")
Identificeren van puntwolkgegevens rond elk rasterpunt
Vervolgens moeten we alle puntenwolkinformatie binnen 100 meter voor gebouwen en hoge vegetatie ophalen, deze worden gebruikt voor SVF-berekening. Voor grondpunten beschouwen we alleen die binnen 10 meter, omdat deze uitsluitend worden gebruikt om de hoogte van elk gridpunt te schatten.
df_selected = df_pc.select("X", "Y", "Z", "Classification")
dome_radius = 100
height_radius = 10
# Registreer als tijdelijke weergaven
df_pc.createOrReplaceTempView("pc_vw")
df_grid.createOrReplaceTempView("grid_vw")
# Voer een ruimtelijke join uit met ST_DWithin met 100 meter
grid_join_pc = spark.sql(f"""
SELECT
g.fid,
ST_X(g.geometry) AS x1,
ST_Y(g.geometry) AS y1,
p.classification,
p.x AS pc_x,
p.y AS pc_y,
p.z AS pc_z,
ST_Distance(g.geometry, p.geometry) AS distance,
g.geometry AS g_geometry,
p.geometry AS pc_geometry
FROM grid_vw g
JOIN pc_vw p
ON ST_DWithin(g.geometry, p.geometry, {dome_radius})
WAAR p.classification IN (5, 6) OF (p.classification = 2 EN ST_DWithin(g.geometry, p.geometry, {height_radius}))
""")
Schatten van de hoogte van roosterpunten op basis van nabijgelegen puntwolkgegevens (straal van 10 m)
Hier bepalen we de hoogte van elk roosterpunt door de dominante omringende klasse, bouw of grond, te identificeren en vervolgens de gemiddelde hoogte van die klasse binnen een gedefinieerde straal te berekenen.
# Filter only classification 2 and 6 and count occurrences of (fid, classification)
grouped = grid_join_pc.filter(
(F.col("classification").isin(2, 6)) & (F.col("distance") <= height_radius)
).groupBy("fid", "classification").count()
# Define window: partition by fid, order by count descending
window_spec = Window.partitionBy("fid").orderBy(F.desc("count"))
# Apply row_number
ranked = grouped.withColumn("rn", F.row_number().over(window_spec))
# Compute the average elevation for each grid point using nearby point cloud data within a specified radius.
grid_pc_elevation = grid_join_pc.join(g_classification_df, on=["fid", "classification"]).filter(
(F.col("distance") <= height_radius)
).groupBy("fid").agg(
(F.sum("pc_z") / F.count("pc_z")).alias("height")
)
# Combine point cloud data with classification info and computed height, optimized with repartitioning.
grid_pc_elevation_all = grid_join_pc.withColumnRenamed("classification", "p_classification").join(g_classification_df, on=["fid"]).join(grid_pc_elevation, on=["fid"]).repartitionByRange(num_partitions, "fid")
# Filter out ground points (e.g., class 2) to retain only buildings and high vegetation points for analysis.
grid_pc_cleaned = grid_pc_elevation_all.filter("p_classification != 2").repartitionByRange(num_partitions, "fid")
Het creëren van de koepel, het genereren van de plot en het berekenen van de SVF
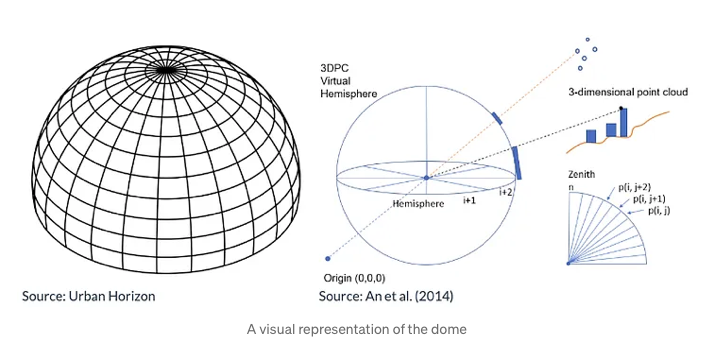
De koepel is een weergave van de hemel, lopend van de horizon tot aan het zenit (recht boven) van het gezichtspunt. De koepel kan worden onderverdeeld in sectoren op basis van horizontale en verticale richtingen, waardoor in wezen een koepelvormig raster ontstaat. De eenheden die worden gebruikt om de sectoren te splitsen zijn 2 graden horizontaal (azimuthhoek) en 1 graad verticaal (elevatiehoek), wat als geschikte waarden voor de berekening wordt beschouwd.
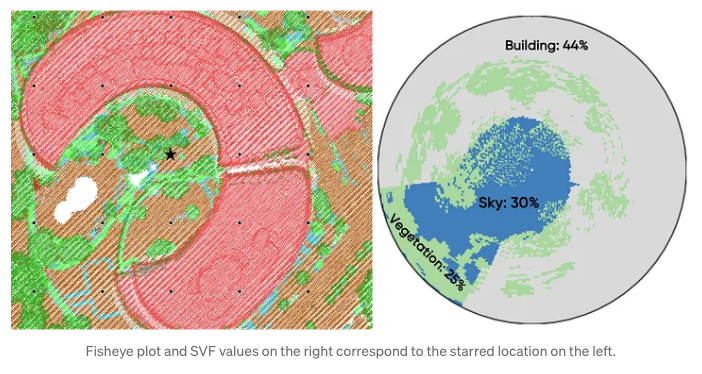
Om de Sky View Factor (SVF) te berekenen, wordt puntwolkdata geprojecteerd op een koepel, verdeeld in sectoren, waarbij wordt aangegeven welke sectoren vanuit het zicht worden geblokkeerd. Het dichtstbijzijnde punt in elke sector bepaalt de obstructie, en als dat punt een gebouw is, worden alle sectoren daaronder in die richting ook als geblokkeerd beschouwd. Het onbelemmerde deel van het oppervlak van de koepel geeft de SVF. Voor de duidelijkheid worden de resultaten gevisualiseerd in een cirkelvormig diagram dat toont welke sectoren open hemel zijn of worden geblokkeerd door gebouwen of vegetatie, georiënteerd op het noorden voor eenvoudige interpretatie.
# Calculate raw azimuth angle (in degrees) from each grid point to each point in the point cloud.
# Shifted by -90 to align with the 0° direction being north.
grid_pc_az = grid_pc_cleaned.withColumn(
"azimuth_raw",
degrees(F.atan2(F.col("pc_y") - F.col("y1"), F.col("pc_x") - F.col("x1"))) - 90
)
# Normalize azimuth angle to fall within the range [0, 360).
grid_pc_az = grid_pc_az.withColumn(
"azimuth",
when(F.col("azimuth_raw") < 0, F.col("azimuth_raw") + 360).otherwise(F.col("azimuth_raw"))
)
# Drop the temporary azimuth_raw column to clean up the DataFrame.
grid_pc_az = grid_pc_az.drop("azimuth_raw")
# Calculate the elevation angle (in degrees) from the grid point to each point in the point cloud.
# Height is divided by 1000 to convert from millimeters to meters if necessary.
grid_pc_az = grid_pc_az.withColumn(
"elevation",
degrees(F.atan2(F.col("pc_z") - F.col("height") / 1000, F.col("distance")))
)
# Bin azimuth angles into 2-degree intervals (0–179 bins for 360°).
grid_pc_az = grid_pc_az.withColumn("azimuth_bin", F.floor(F.col("azimuth") / 2))
# Get the minimum elevation angle across all records to define the lower bound of elevation bins.
min_val = F.lit(grid_pc_az.select(F.min("elevation")).first()[0])
# Get the maximum elevation angle across all records to define the upper bound of elevation bins.
max_val = F.lit(grid_pc_az.select(F.max("elevation")).first()[0])
# Compute bin width by dividing elevation range into 89 equal parts (90 bins total).
bin_width = (max_val - min_val) / 89
# Bin elevation angles into 90 intervals, ensuring they stay within the [0, 89] range.
grid_pc_az = grid_pc_az.withColumn("elevation_bin",
F.least(
F.greatest(
F.floor(
(F.col("elevation") - F.lit(min_val)) /
F.lit((max_val - min_val)/90)
).cast("int"),
F.lit(0) # Clamp minimum bin index to 0
),
F.lit(89) # Clamp maximum bin index to 89
)
)
# Define a window that partitions the data by azimuth and elevation bins,
# and orders points within each bin by their distance to the grid point.
window_spec = Window.partitionBy("azimuth_bin", "elevation_bin").orderBy("distance")
# Assign a row number within each azimuth-elevation bin, so the closest point (smallest distance) gets rank 1.
df_with_rank = grid_pc_az.withColumn("rn", F.row_number().over(window_spec))
# Keep only the closest point (rank 1) in each bin and drop the temporary rank column.
# Then repartition the result by 'fid' to optimize parallel processing in subsequent steps.
closest_points = df_with_rank.filter(col("rn") == 1).drop("rn").repartitionByRange(num_partitions, "fid")
def create_dome(pdf: pd.DataFrame, max_azimuth: int = 180, max_elevation: int = 90) -> np.ndarray:
"""
Maakt een koepelmatrix op basis van azimut- en elevatieklassen, waarbij rekening wordt gehouden met obstructies door gebouwen.
"""
dome = np.zeros((max_azimuth, max_elevation), dtype=int)
domeDists = np.zeros((max_azimuth, max_elevation), dtype=float)
for _, row in pdf.iterrows():
a = int(row["azimuth_bin"])
e = int(row["elevation_bin"])
dome[a, e] = row["p_classification"]
domeDists[a, e] = row["distance"]
# Markeer delen van de koepel die worden belemmerd door gebouwen
if np.any(dome == 6): # 6 = gebouwen
bhor, bver = np.where(dome == 6)
builds = np.stack((bhor, bver), axis=-1)
shape = (builds.shape[0] + 1, builds.shape[1])
builds = np.append(builds, (bhor[0], bver[0])).reshape(shape)
azimuth_change = builds[:, 0][:-1] != builds[:, 0][1:]
keep = np.where(azimuth_change)
roof_rows, roof_cols = builds[keep][:, 0], builds[keep][:, 1]
for roof_row, roof_col in zip(roof_rows, roof_cols):
condition = np.where(np.logical_or(
domeDists[roof_row, :roof_col] > domeDists[roof_row, roof_col],
dome[roof_row, :roof_col] == 0
))
dome[roof_row, :roof_col][condition] = 6
return dome
# Plot dome
def generate_plot_image(dome):
# Maak cirkelvormig raster
theta = np.linspace(0, 2*np.pi, 180, endpoint=False)
radius = np.linspace(0, 90, 90)
theta_grid, radius_grid = np.meshgrid(theta, radius)
Z = dome.copy().astype(float)
Z = Z.T[::-1, :] # Transponeren en verticaal spiegelen
Z[Z == 0] = 0
Z[np.isin(Z, [5])] = 0.5
Z[Z == 6] = 1
if Z[Z == 6].size == 0:
Z[0, 0] = 1 # Dwing de plot om iets weer te geven
fig = plt.figure(figsize=(4, 4))
ax = fig.add_subplot(111, projection='polar')
cmap = plt.get_cmap('tab20c')
ax.pcolormesh(theta, radius, Z, cmap=cmap)
ax.set_ylim([0, 90])
ax.tick_params(labelleft=False)
ax.set_theta_zero_location("N")
ax.set_xticks([])
ax.set_yticks([])
buf = io.BytesIO()
plt.savefig(buf, format='png', bbox_inches='tight', pad_inches=0)
plt.close(fig)
buf.seek(0)
img_base64 = base64.b64encode(buf.read()).decode('utf-8')
return img_base64
def process_and_plot(pdf: pd.DataFrame) -> pd.DataFrame:
fid = pdf["fid"].iloc[0]
# Maak dome met obstructie door gebouwen/vegetatie
dome = create_dome(pdf)
# Genereer een base64-gecodeerde fisheye-plotafbeelding
plot_base64 = generate_plot_image(dome)
# Bereken SVF- en obstructiemetrics
SVF, tree_percentage, build_percentage = calculate_SVF(100, dome)
return pd.DataFrame(
[[fid, dome.tolist(), plot_base64, SVF, tree_percentage, build_percentage]],
columns=["fid", "dome", "plot", "SVF", "treeObstruction", "buildObstruction"]
)
Resultaten
Zoals je in de bovenstaande code kunt zien, zijn sommige onderdelen nog steeds afhankelijk van NumPy-structuren voor bewerkingen zoals koepelconstructie, plotting en SVF-berekening. Aangezien elk roosterpunt overeenkomt met een enkele koepel, kunnen we deze NumPy-gebaseerde functies per rij veilig toepassen. Om dit efficiënt te doen in PySpark, , zonder al te veel code refactoring, ik gebruik de toepassenInPandas methode. Dit stelt ons in staat om onze bestaande Pandas-gebaseerde logica rechtstreeks toe te passen op elke groep rijen (gegroepeerd per de "grappen" kolom) binnen de PySpark DataFrame. Op deze manier kunnen we gedistribueerde verwerking in Spark benutten terwijl we bestaande, goed geteste NumPy-code hergebruiken voor de dome- en SVF-berekeningen.
# Gewenst schema
output_schema = StructType([
StructField("fid", IntegerType()),
StructField("dome", ArrayType(ArrayType(IntegerType()))),
StructField("plot", StringType()),
StructField("SVF", FloatType()),
StructField("treeObstruction", FloatType()),
StructField("buildObstruction", FloatType())
])
result_df = closest_points.groupBy("fid").applyInPandas(process_and_plot, schema=output_schema)
result_df.write.mode("overwrite").saveAsTable(f"geospatial.pointcloud.wasahington_grid")
# Fetch the the grid point with fid = 105 for a sample visualization
pdf = result_df.filter("fid = 105").select("fid", "plot").toPandas()
for index, row in pdf.iterrows():
# Decode base64 string to bytes
img_bytes = base64.b64decode(img_base64)
# Load image with PIL
image = Image.open(io.BytesIO(img_bytes))
# Display using matplotlib (preserves original colors)
plt.figure(figsize=(6, 6))
plt.imshow(image)
plt.axis('off') # Hide axes
plt.show()
Wat is hierna?
In onze live training “Databricks Geospatial in een dag” bij RevoData Kantoor, zullen we dieper ingaan op de logica achter deze code en dit voorbeeld gebruiken om te demonstreren hoe u:
- Zet een cluster op dat in staat is om point cloud-gegevens te verwerken
- Visualiseer LiDAR-puntwolken rechtstreeks in Databricks
- Efficiënt partitioneren van point cloud-gegevens voor gedistribueerde verwerking
- Pak de uitdagingen aan van code migratie en minimale refactoring
Pak hier je plek voor de training via onderstaande link, ik kijk ernaar uit je daar te zien!
https://revodata.nl/databricks-geospatial-in-a-day/

Melika Sajadian
Senior Geospatial Consultant bij RevoData, die haar kennis over Databricks Geospatial met u deelt