SQL Server vs Apache Spark: Een Diepe Duik in de Verschillen in Uitvoering
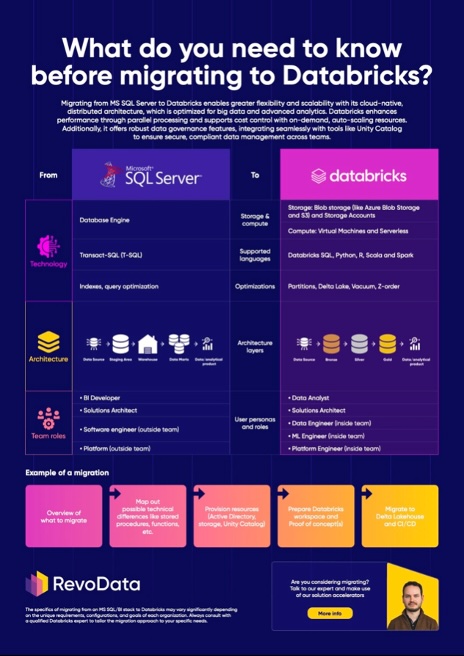
De manier waarop SQL Server en Apache Spark (de ruggengraat van Databricks) queries verwerken, verschilt fundamenteel. Het begrijpen van deze verschillen is cruciaal bij het migreren of optimaliseren van workloads. Terwijl SQL Server afhankelijk is van een single-node, transactie-geoptimaliseerde uitvoeringsengine, is Spark in Databricks gebouwd voor gedistribueerde, parallelle verwerking.
Uitvoeringsmodel: Single-Node versus gedistribueerde verwerking
SQL Server voert query's uit binnen een single-node omgeving, wat betekent dat alle bewerkingen – zoals joins, aggregaties en filtering – plaatsvinden op een gecentraliseerde databaseserver. De query-optimizer bepaalt het beste uitvoeringsplan en maakt gebruik van indexen, statistieken en caching om de efficiëntie te verbeteren. De prestaties worden echter uiteindelijk beperkt door de resources (CPU, geheugen en schijf) van één enkele machine.
Databricks, aangedreven door Apache Spark, verdeelt de uitvoering van queries over meerdere knooppunten in een cluster. In plaats van een enkel uitvoeringsplan dat op één server werkt, breekt Spark queries op in kleinere taken, die parallel worden uitgevoerd op worker-knooppunten. Deze aanpak stelt Databricks in staat om enorme datasets efficiënt te verwerken, waarbij geheugen- en computerbronnen worden benut over een gedistribueerd systeem.
Query Uitvoering Uitsplitsing
- SQL Server Een query wordt geparsed, geoptimaliseerd tot een uitvoeringsplan, en uitgevoerd op een enkele machine. Het leest data van de schijf (of uit het geheugen indien gecached), verwerkt deze met behulp van indexen en statistieken, en retourneert resultaten.
- Databricks (Spark): Een query wordt geparsed en getransformeerd naar een Directed Acyclic Graph (DAG), die vervolgens wordt opgedeeld in fasen en taken. De Spark scheduler distribueert deze taken over worker nodes, waar berekeningen zoveel mogelijk in het geheugen worden uitgevoerd voordat resultaten terug worden geschreven naar opslag.
Gegevens schudden en joinen
Een van de grootste verschillen tussen de twee systemen is hoe ze omgaan met joins en aggregaties.
- SQL Server Omdat alle gegevens op één machine worden verwerkt, zijn joins sterk afhankelijk van indexen en sortering. Als indexen ontbreken of inefficiënt zijn, kunnen bewerkingen zoals hash joins of merge joins leiden tot dure schijf-I/O.
- Databricks (Spark): Joins vereisen shuffling, waarbij gegevens over knooppunten worden herverdeeld om ervoor te zorgen dat overeenkomende sleutels op dezelfde worker terechtkomen. Dit introduceert netwerkoverhead, maar maakt massale schaalbaarheid mogelijk. Technieken zoals uitzendingenjoins (het versturen van een kleine tabel naar alle knooppunten) helpt de shuffle-kosten te verlagen en de prestaties te verbeteren.
Caching en opslagoptimalisatie
OptSQL Server is afhankelijk van de buffer pool om veelgebruikte gegevens in het geheugen te cachen, waardoor schijfleesacties worden geminimaliseerd. Geïndexeerde gegevens worden efficiënt op schijf opgeslagen en uitvoeringsplannen worden gecachet voor hergebruik.
Databricks profiteert daarentegen van in-memory caching met behulp van de cachingfunctie van Spark, waardoor herhaalde leesacties vanuit cloudopslag (bijv. Azure Blob of AWS S3) worden verminderd. Daarnaast helpen technieken zoals Z-ordering en partitionering bij het optimaliseren van de gegevensindeling, waardoor de scantijden voor grote datasets worden verkort.
Fouttolerantie en schaalbaarheid
SQL Server werkt met ACID-transacties en hoge beschikbaarheidsmechanismen zoals Always On Availability Groups, maar het mist ingebouwde fouttolerantie bij query-uitvoering. Als een proces faalt, moet het opnieuw worden gestart.
Databricks biedt via Spark fouttolerantie via lineage en herberekening. Als een knooppunt uitvalt, herstart Spark alleen de getroffen taken, wat zorgt voor veerkracht zonder handmatige tussenkomst. Bovendien maakt horizontale schaalbaarheid het mogelijk om dynamisch op te schalen op basis van werkbelastingvereisten.
Wil je meer weten?
Overweegt u workloads te migreren van SQL Server naar Databricks? Het begrijpen van uitvoeringsmodellen is essentieel voor het ontwerpen van efficiënte queries en het vermijden van prestatieproblemen. Laten we contact leggen en bespreken hoe we uw overgang soepel kunnen laten verlopen!

Rafal Frydrych
Senior Consultant bij RevoData, deelt zijn kennis met u in de opiniërende serie: Migreren van MSBI naar Databricks.